DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
4.5 (228) In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re
modules/data_parallel.py at master · RobertCsordas/modules · GitHub

Wrong gradients when using DistributedDataParallel and autograd
DistributedDataParallel does not get the same grad at all. · Issue
If a module passed to DistributedDataParallel has no parameter

Cannot update part of the parameters in DistributedDataParallel

Distributed Data Parallel and Its Pytorch Example
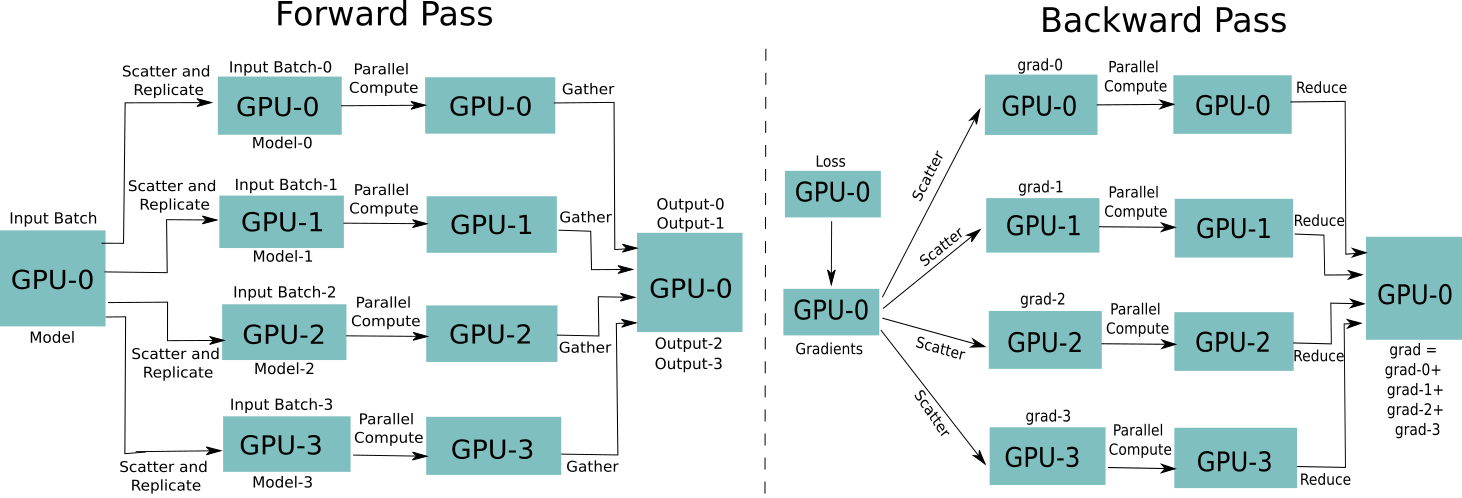
Pytorch 並列 DataParallel/DistributedDataParallelについて - 適当な

Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First

Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First
Don't understand why only Tensors of floating point dtype can

torch.distributed.barrier Bug with pytorch 2.0 and Backend=NCCL

Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First

Issue for DataParallel · Issue #8637 · pytorch/pytorch · GitHub
Dtydtpe Clearance Sales, Bras for Women, Low Cut Bra for Women's
Dtydtpe Clearance Sales, Bras for Women, Womens 3Pcs Solid Color
Dtydtpe decoração do quarto decoração de casa Caixa de Correio
Dtydtpe Bras for Women, Women Strap and Shoulder Straps with Non-Slip Placket Bra Underwear Blacka
Frontiers Tracking a Circular Economy Transition Through Jobs
 High Class Jumpsuit - Navy
High Class Jumpsuit - Navy nsendm Female Underpants Adult No Line Panties for Women Bikini Women's Cotton Flat Leg Pants Breathable Sexy Mid Waist Solid Womens Undies Size(Mint
nsendm Female Underpants Adult No Line Panties for Women Bikini Women's Cotton Flat Leg Pants Breathable Sexy Mid Waist Solid Womens Undies Size(Mint 5 Top Benefits of Swimming. Nike JP
5 Top Benefits of Swimming. Nike JP Calvin Klein Men's Boxer X Micro Low Rise U8802 Trunk Ck Underwear
Calvin Klein Men's Boxer X Micro Low Rise U8802 Trunk Ck Underwear Nursing Bras for Breastfeeding,Jelly Strip High Support Seamless Maternity Bra, Comfortable Full-Coverage,Cloud Feel
Nursing Bras for Breastfeeding,Jelly Strip High Support Seamless Maternity Bra, Comfortable Full-Coverage,Cloud Feel Sanuk Women's Yoga Sling 2 Flip Flop : : Clothing
Sanuk Women's Yoga Sling 2 Flip Flop : : Clothing